[:de]Digitale Langzeitarchivierung verstehen – heute und morgen[:en]Understanding long-term preservation – today and tomorrow[:]
[:de]

DigitalPreservationCoalition (https://www.dpconline.org/events/world-digital-preservation-day/wdpd-logos)
Anlässlich des World Digital Preservation Day möchten wir die digitale Langzeitarchivierung thematisieren. Natürlich ist keine Tour d’Horizon möglich, zu vielfältig und komplex ist das Thema. Vielmehr soll dieser Blogbeitrag die Langzeitarchivierung als kontinuierlichen und kommunikativen Prozess aufgreifen.
Herausforderungen der digitalen Langzeitarchivierung
Digitale Langzeitarchivierung kann als die Sicherstellung des Erhalts, der Zugänglichkeit und Nutzbarkeit digitaler Daten definiert werden. Was einfach klingt, stellt in der Praxis eine grosse Herausforderung dar. Daten sind Informationen in kodierter Form, welche nur mit geeigneter Software betrachtet und nur auf nicht dauerhaft stabilen Trägern (z.B. Festplatten) gespeichert werden können. Defekte können ohne Vorwarnung auftreten und im ungünstigsten Fall zum Totalverlust der Information führen, zumindest aber eine aufwändige Wiederherstellung notwendig machen. Lesen Sie dazu auch die Explora-Story «Surfen im Datenmeer». Im Gegensatz dazu lässt sich ein frühzeitig erkannter Schaden an einem physischen Objekt, wie zum Beispiel an einem Buch oder einem Brief mit geeigneten konservatorischen Massnahmen beheben oder stabilisieren und so einem Teil- oder Totalverlust des Bildinhaltes zuvorkommen.
Daten technisch sicherstellen
In der digitalen Langzeitarchivierung geht es also darum, der Instabilität des Datenträgers entgegenzuwirken und den aus Nullen und Einsen bestehende Code, auch als Bitstream bezeichnet, jederzeit korrekt interpretierbar und nutzbar zu halten.
Dem Speicherproblem können wir mit Backups und der Erneuerung alternder Hardware begegnen. Für die Erhaltung des Bitstreams steht uns Software zur Verfügung, die mittels eines Algorithmus eine eindeutige Prüfsumme erstellt, mit welcher die Unversehrtheit des Datenstroms sichergestellt werden kann.
Interpretierbarkeit von Daten sicherstellen
Für die Sicherstellung der Interpretierbarkeit machen wir uns darüber Gedanken, welche Formate am besten geeignet sind und welche Metadaten wir aufbewahren. Somit kann die Lesbarkeit der Daten über die Jahre gewährleistet werden. Dabei gehen wir davon aus, dass die rasch voranschreitende technologische Entwicklung die permanente Pflege der Daten und früher oder später die Migration, d.h. die Umwandlung in neue Formate, erfordert. Ein anderer Ansatz ist die Emulation, also ein «Nachbau» einer geeigneten Software-Umgebung, mit welcher die Daten interpretiert und genutzt werden können.
Digitale Langzeitarchivierung als kontinuierliche Kommunikation
Als Voraussetzung für beide Ansätze kann die Langzeitarchivierung als permanenter Kommunikationsprozess betrachtet werden. Wir kommunizieren die nach unserem Wissen notwendigen Informationen an mehr oder weniger unbekannte Empfänger in naher oder ferner Zukunft. Wir überlegen uns heute, was für die Interpretation der Daten in einem spezifischen, uns unbekannten Umfeld notwendig sein wird. Idealerweise ist das von uns geschnürte und archivierte Paket bestehend aus den Daten und seinen Metadaten selbsterklärend, so dass ein uns unbekannter Empfänger ohne weitere Rückfragen die Daten lesen und interpretieren kann.
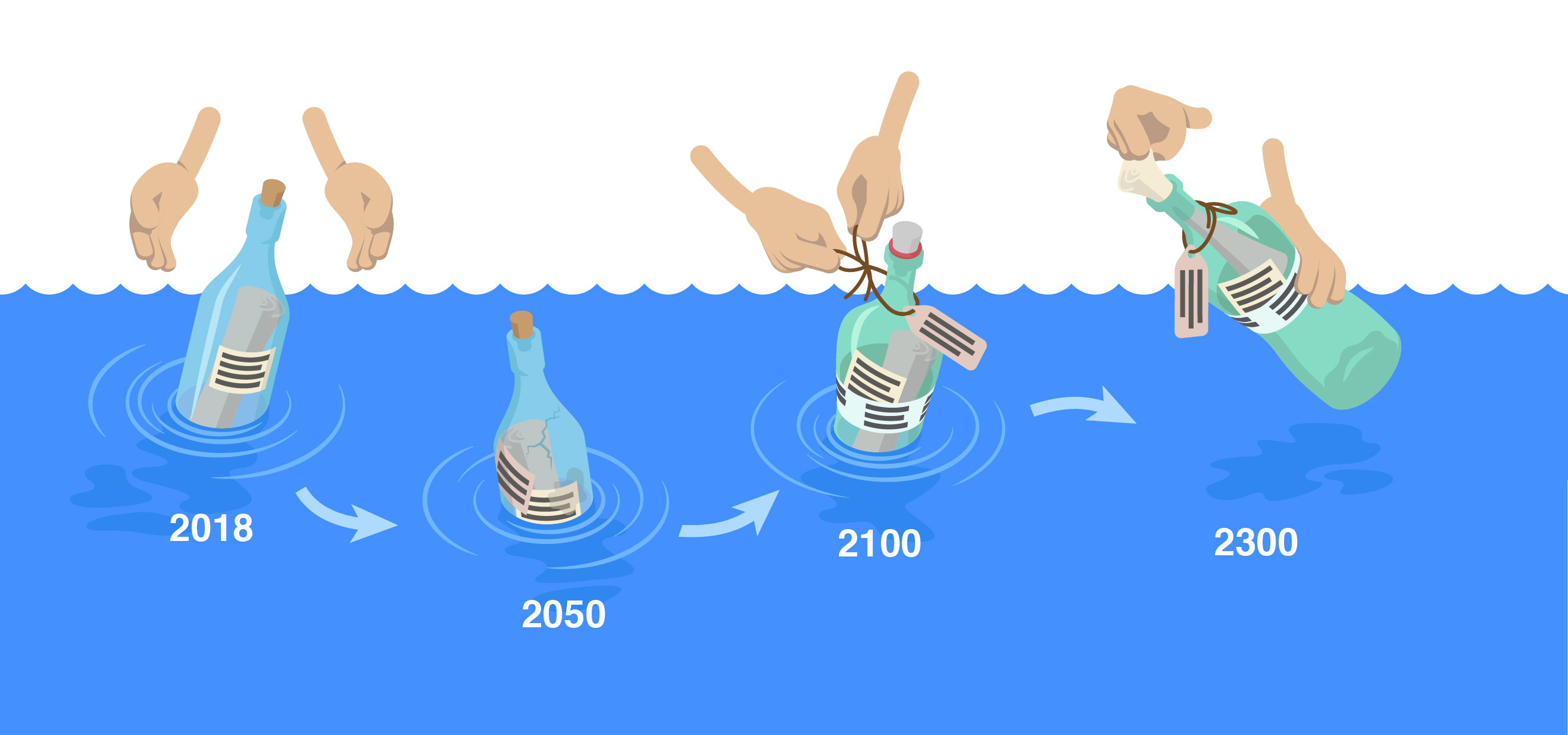
Illustration: Andres Bucher
Trotzdem sind unsere Bemühungen nicht als reine Flaschenpost zu verstehen, die in tausenden von Jahren vielleicht gefunden wird. Vielmehr dürfte die Kontinuität dieser Kommunikationstätigkeit über Generationen hinweg für den Erfolg der Langzeitarchivierung entscheidend sein. Neben den (Meta-)Daten, die wir heute als wichtig oder absolut notwendig definieren, werden durch den Einsatz neuer Formate und Software auch neue Metadaten anfallen, welche ebenso wichtig sein werden. Diesen Informationszyklus und die Kontinuität der Überlieferung gilt es nicht abreissen zu lassen.
Das Data Archive der ETH Zürich
Um also die Behältnisse bruchsicher und die Etiketten lesbar zu halten, dafür setzen wir uns tagtäglich im Forschungsdatenmanagement und Datenerhalt ein. Mit dem Data Archive betreiben wir eine Langzeitarchivierungslösung für die ETH Zürich, die etwa für die Sicherung digitaler Sammlungen oder für den Erhalt digitaler Publikationen und Forschungsdaten aus der Research Collection eingesetzt wird.
Bitte zögern Sie nicht, uns zu kontaktieren. Gerne beantworten wir all Ihre Fragen oder beraten Sie bei Ihrem nächsten Forschungsvorhaben.[:en]

DigitalPreservationCoalition (https://www.dpconline.org/events/world-digital-preservation-day/wdpd-logos)
To mark the World Digital Preservation Day we would like to address the topic of long-term preservation. Needless to say, a comprehensive overview is out of the question; the topic is just too diverse and complex. Instead, this blog entry aims to examine long-term preservation as an ongoing and communicative process.
Challenges of digital long-term preservation
Digital long-term preservation can be defined as safeguarding the curation, accessibility and usability of digital data. What might sound straightforward enough actually poses a major challenge in practice. Data is information in an encoded form which can only be viewed with suitable software and only saved on storage devices (e.g. hard drives) that are not permanently stable. Defects can occur without prior warning, at worst causing the information to be lost entirely, at best necessitating a complicated recovery. Read the Explora story Surfing the sea of data for further information on this. By contrast, damage to a physical object such as a book or letter which has been spotted at an early stage can be repaired or stabilised with appropriate conservational methods, thereby preventing the partial or total loss of the item.
Safeguarding data technically
Long-term preservation of digital data therefore boils down to countering the instability of the storage medium and ensuring that the binary code, also known as the bitstream, can always be interpreted and used correctly.
We are able to tackle the storage problem with backups and by replacing ageing hardware. To preserve the bitstream, we have software at our disposal that creates a clear check sum using an algorithm which enables the integrity of the data flow to be guaranteed.
Guaranteeing the interpretability of data
To guarantee interpretability, we contemplate which formats are best suited and which metadata we store. This guarantees the legibility of the data. In doing so, we assume that the rapidly progressing technological development will necessitate the permanent upkeep of the data and sooner or later migration, i.e. conversion into new formats. Another approach is emulation, i.e. a “replica” of a suitable software environment, with the aid of which the data can be used and interpreted.
Digital long-term archiving as continuous communication
Long-term preservation as a permanent communication process can be regarded as a prerequisite for both approaches. We will communicate the information we deem necessary to more or less unknown recipients in the near or distant future. We consider today what will be necessary to interpret the data in a specific environment that is unknown to us. Ideally, the package comprising data and its metadata which we have put together and archived will be self-explanatory so a recipient whom we do not know can read and interpret the data without any further queries.
Illustration: Andres Bucher
Nevertheless, our efforts should not be taken as a pure message in a bottle that might be discovered in thousands of years. Instead, the continuity of these communication activities may be crucial for the success of long-term archiving for generations to come. Besides the (meta) data we define as important or absolutely necessary today, new metadata that will be just as important will also accumulate through the use of new formats and software. This information cycle and the continuity of the transfer must not be broken.
ETH Data Archive
Therefore, to save the data and metadata safely for the medium and long term, we champion daily research data management and digital curation. With the Data Archive we run a long-term archiving solution for ETH Zurich that is used to safeguard digital collections or preserve digital publications and research data in the Research Collection, for instance.
Please don’t hesitate to contact us. We would be glad to answer any questions you may have or advise you on your next research project: data-archive@library.ethz.ch[:]