[:de]Das neue Webarchiv der ETH Zürich[:en]The new ETH Zurich Web Archive[:]
[:de]
Ein Beitrag zum ersten internationalen “Digital Preservation Day”
Wollten Sie auch schon mal eine Website aufrufen, nur um festzustellen, dass es sie gar nicht mehr gibt?
Der erste internationale Digital Preservation Day soll das Bewusstsein dafür schärfen, dass die langfristige Erhaltung des kulturellen Erbes im digitalen Zeitalter neue Arbeitsprozesse und Lösungen erfordert. Auch die ETH-Bibliothek beschäftigt sich mit diesen Fragen. Um den Webauftritt der ETH Zürich (und damit eine der wichtigsten Quellen zur Geschichte unserer Hochschule) zu sichern, engagiert sich das Hochschularchiv der ETH Zürich im Bereich der Webarchivierung. Seit Ende 2017 steht das neue Webarchiv der ETH Zürich allen Nutzerinnen und Nutzern zur Verfügung.
Mehrwert im Vergleich zu anderen Webarchiven
Während das Internet Archive in erster Linie durch die Masse an archivierten Websites besticht, investiert das Hochschularchiv seine Ressourcen gezielt in die Qualität des ETH-Webarchivs:
- Systematische Auswahl
- Qualitätssicherung (z.B. Vollständigkeit der Inhalte einer Website)
- Professionelle Beschreibung durch Metadatierung
- Langfristige Zugänglichkeit
- Wissenschaftliche Zitierfähigkeit
Das Hochschularchiv wird dabei unterstützt durch die Informatikdienste der ETH Zürich, die den Webcrawler betreiben, und durch das ETH Data Archive der ETH-Bibliothek, das die Daten langfristig sichert und zugänglich erhält.

In der Kopfzeile der Webseite ist deutlich markiert, dass es sich um eine archivierte Version handelt.
Im Bild ein Snapshot der ETH-Hauptseite von 2013
An der ETH Zürich gibt es eine Tradition im Bereich Webarchivierung. Dank einer Einzelinitiative, abrufbar auf http://www.archiv.ethz.ch/, können einige wichtige Sites bereits jetzt in historischer Perspektive betrachtet werden. Im Webarchiv des Hochschularchivs werden die wichtigsten Teile des Webauftritts der ETH Zürich regelmässig gesichert: die Hauptseite, die Portale für ETH-Angehörige und Studierende und die sogenannten Fachsites, also die Websites der Institute und Professuren.
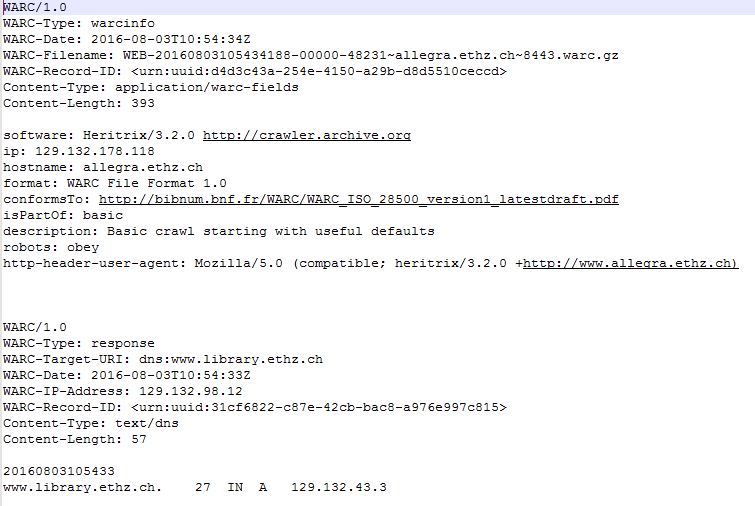
ETH-Websites werden mit dem Webcrawler Heritrix geharvestet. Dabei entsteht ein Container im WARC-Format, der alle Elemente der Website enthält. Im Bild ein Ausschnitt aus dem Header einer WARC-Datei.
Herausforderungen für die Digital Preservation
Wie kann sichergestellt werden, dass archivierte Websites langfristig verfügbar bleiben? Eine Grundvoraussetzung ist sicherlich die verlässliche, redundante und örtlich separierte Mehrfachspeicherung. Dies wird an der ETH Zürich durch die Informatikdienste gewährleistet. Darüber hinaus ist der fachliche Einsatz der Digital Preservation Manager gefordert. Um rechtzeitig die für die Preservation erforderlichen Massnahmen treffen zu können, wird die Entwicklung der verwendeten Dateiformate kontinuierlich beobachtet. Beispielsweise muss möglichst frühzeitig erkannt werden, ob das aktuelle Standardformat zur Archivierung von Websites (WARC) durch ein neues abgelöst wird, oder ob die im Einsatz stehenden Viewer noch unterstützt werden. Diese Aufgabe gilt es im Übrigen auch für die in der Website eingebetteten Objekte wie PDFs, Bilder und Videos wahrzunehmen. Die Verantwortung hierfür liegt beim ETH Data Archive.
Der erste International Digital Preservation Day wird durch die Digital Preservation Coalition organisiert
Wo wir uns Innovationen wünschen
Zurzeit ist die Webarchivierung eine personalintensive Aufgabe, vor allem im Bereich Qualitätssicherung und Metadatierung. Hier könnten Arbeitsschritte automatisiert werden, beispielsweise durch die Entwicklung eines Tools, das die Bildpunkte einer archivierten Website mit den Bildpunkten der Originalwebsite vergleicht und so die Qualität der archivierten Website automatisch einstuft. Auch bei der Metadatierung der Websites wäre es nützlich, den Titel einer Website und das Datum der letzten Änderungen automatisch auslesen zu können.
Suchen, finden und zitieren
Das Webarchiv der ETH Zürich ist über verschiedene Suchportale zugänglich:
- Hochschularchiv online
- Wissensportal der ETH-Bibliothek
- und bald auch im Archives Portal Europe
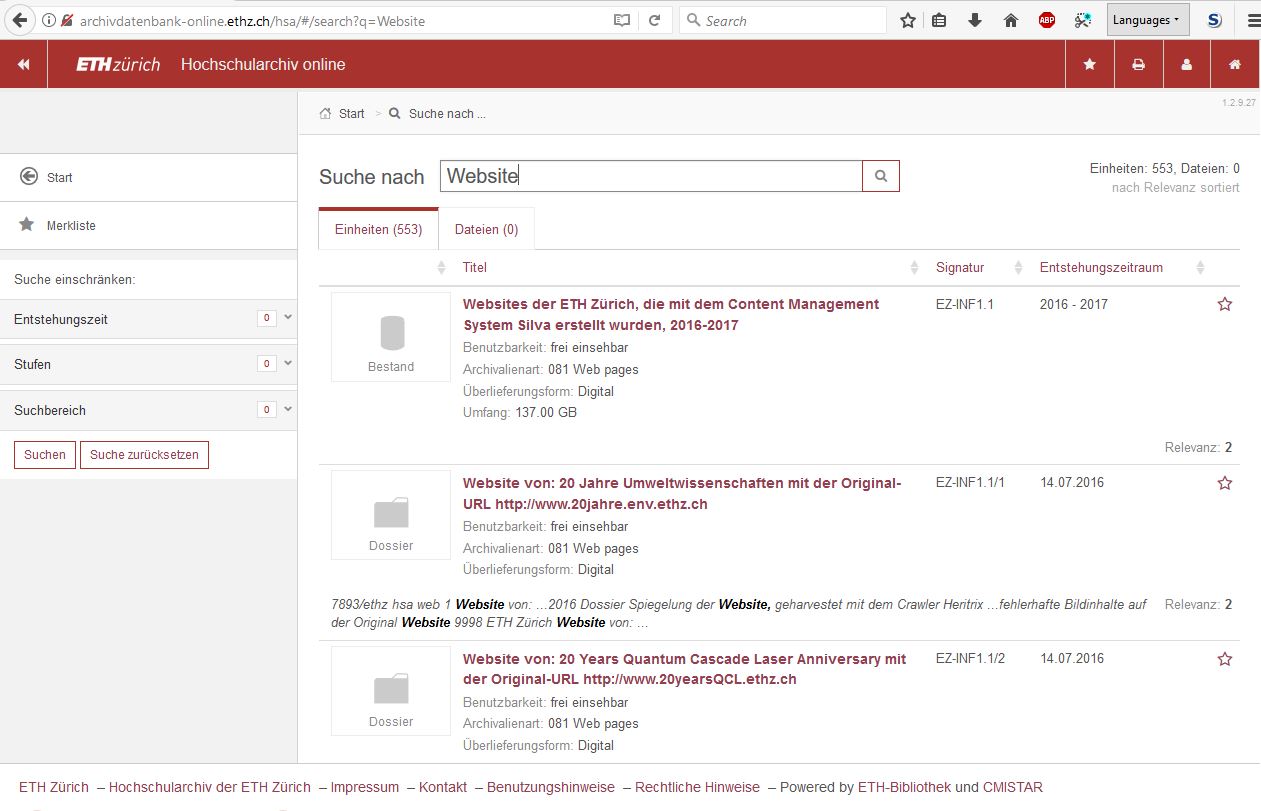
Verschiedene Suchportale machen die Suche in den Metadaten des ETH Webarchivs möglich. Im Bild eine Trefferliste aus dem Suchportal Archivdatenbank Online.
Die einzelnen Snapshots, also die zu verschiedenen Zeitpunkten archivierten Versionen einer Website, besitzen jeweils einen Digital Object Identifier (DOI). Somit können sie als wissenschaftliche Quelle zitiert werden und sind langfristig auffindbar.
Möchten Sie Ihre ETH-Website im Webarchiv der ETH Zürich sichern? Dann melden Sie sie beim Hochschularchiv und schreiben uns eine E-Mail: archiv@library.ethz.ch
Dieses Werk unterliegt einer Creative Commons Attribution-ShareAlike 4.0 International Public License.
![]() [:en]
[:en]
A contribution to the first international “Digital Preservation Day”
Have you ever tried to access a website only to find that it is not available anymore?
The first international Digital Preservation Day aims to raise awareness of new processes and solutions in long-term preservation of cultural heritage in the digital age. ETH Library is also active in this area. In order to preserve ETH Zurich’s web presence (and thus one of the most important sources on the history of our university), the ETH Zurich University Archives has embarked on a web archiving initiative. Since the end of 2017, the new ETH Zurich Web Archive has been available to the public.
Added value compared to other web archives
While the mass of archived websites in the Internet Archive is truly impressive, the University Archives purposefully invests in the quality of its web archive in the following ways:
- Systematic selection of websites
- Quality assurance (e.g. comprehensiveness of the content)
- Professional description and metadata
- Long-term accessibility
- Persistent identifier for scientific citation
The University Archives cooperates closely with the ETH IT Services which operate the web crawler, and also with the ETH Data Archive (ETH Library) which provides long-term data storage and access.
The banner at the top of the website clearly indicates that it is an archived version.
The illustration shows a snapshot of ETH Zurich’s main site from 2013
At ETH Zurich, there is a tradition of web archiving. Thanks to an earlier initiative (available at http://www.archiv.ethz.ch/), some important websites are still accessible for historical purposes. The new ETH Web Archive regularly captures the most important parts of the university’s web presence: its main page, the portals for ETH members and students as well as special interest websites, i.e. institute and research group websites.
ETH websites are harvested using the web crawler Heritrix creating a container in WARC format holding all elements of the website. The illustration shows a section in the header of a WARC file.
Challenges for digital preservation
How can we ensure that our archived websites remain available in the long term? Reliable and geo-redundant storage is certainly a basic requirement and is provided by ETH IT Services. At ETH Library, our Digital Preservation Managers provide additional expertise by monitoring the evolution of file formats in order to ensure long-term preservation. It is essential to detect as early as possible whether the current standard format for web archive initiative (WARC) is being replaced by a new format and whether the web viewers in use are still supported. Of course, this task also applies to objects embedded in the websites, for example PDFs, images, and videos. The responsibility for this lies with the ETH Data Archive.
The first International Digital Preservation Day is organized by the Digital Preservation Coalition
Where we would like to see innovation
Web archiving is a labour-intensive process, especially in regards to quality assurance and cataloguing. It would be useful to develop a tool which compares the pixels of the archived website with the pixels of the original website thus automatically grading the quality of the archived version. It would also be useful if a website’s title and date of last activity were automatically read out to the metadata fields.
How to search and quote
The ETH Zurich Web Archive is accessible via various online portals:
- Hochschularchiv Online (University Archives Information System)
- ETH Library’s Knowledge Portal
- and soon Archives Portal Europe
The metadata of the ETH Web Archive is accessible in various search portals. The illustration shows a list of research results from the University Archives Information System.
Every snapshot, i.e. the versions of a website archived at different times, is assigned a Digital Object Identifier (DOI). Thus, users can cite these snapshots as sources in their scientific publications.
Would you like to save your ETH website in the ETH Zurich Web Archive? To register, please email archiv@library.ethz.ch.
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International Public License.
![]() [:]
[:]